分布式训练
分布式训练
参考文章:
Optimizer state sharding (ZeRO) - 知乎 (zhihu.com)写的很好很详细
模型训练流程
1、正向传播计算出output
2、反向传播计算梯度
3、得到梯度后,用optimizer优化参数
数据并行
DP
DP只能在一个主机上多个GPU间进行分布式训练。
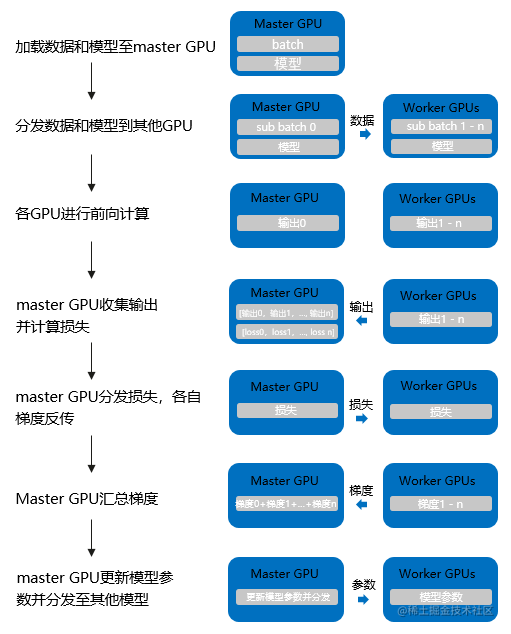
流程:
- 将 inputs 从主 GPU 分发到所有 GPU 上。
- 将 model 从主 GPU 分发到所有 GPU 上。
- 每个 GPU 分别独立进行前向传播,得到 outputs。
- 将每个 GPU 的 outputs 发回主 GPU。
- 在主 GPU 上,通过 loss function 计算出 loss,对 loss function 求导,求出损失梯度。
- 计算得到的梯度分发到所有 GPU 上。
- 反向传播计算参数梯度。
- 将所有梯度回传到主 GPU,通过梯度更新模型权重。
- 不断重复上面的过程
DDP
可以在不同主机的GPU进行分布式训练
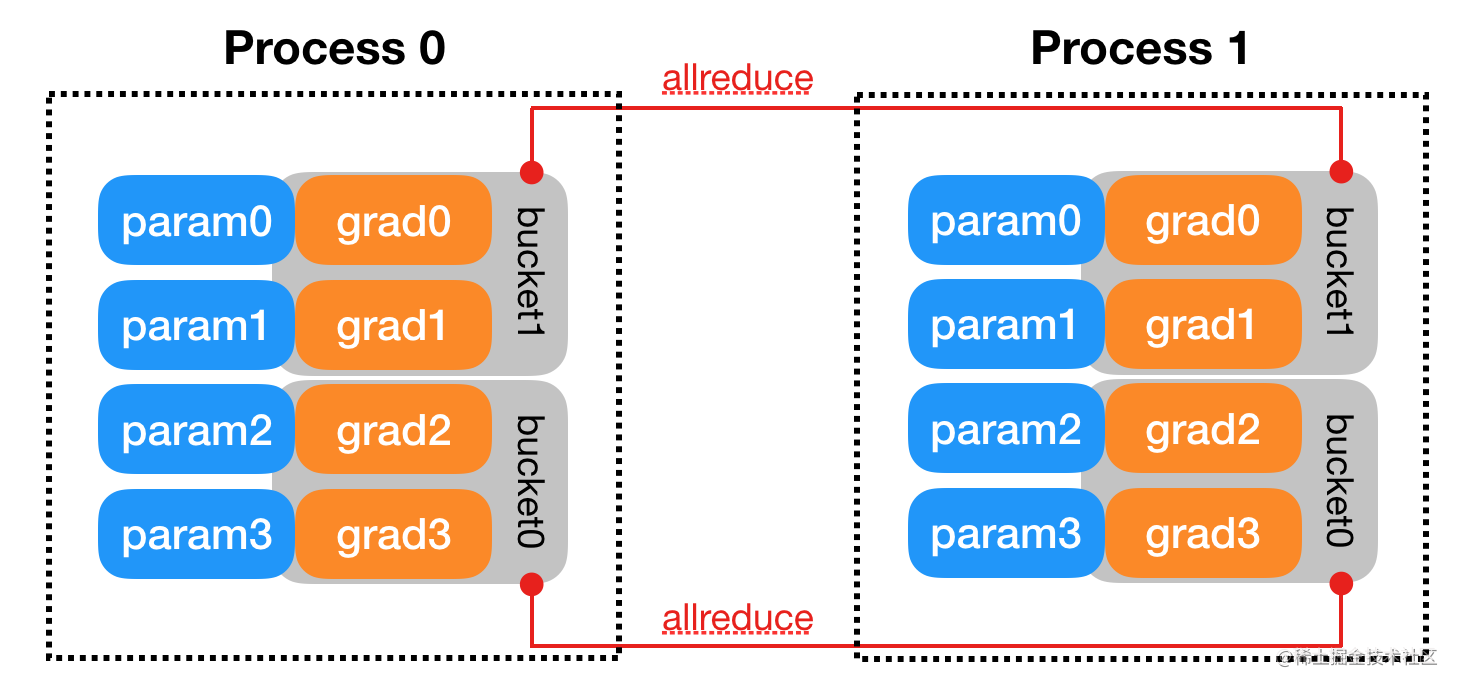
下面rank代表一个worker
- 首先将 rank=0 进程中的模型参数广播到进程组中的其他进程;
- 然后,每个 DDP 进程都会创建一个 local Reducer 来负责梯度同步。
- 在训练过程中,每个进程从磁盘加载 batch 数据,并将它们传递到其 GPU。独立完成向前传播,计算出loss。
- 反向传播过程中,梯度在各个 GPUs 间进行 All-Reduce,每个 GPU 都收到其他 GPU 的梯度,从而可以独自进行反向传播和参数更新。同时,每一层的梯度不依赖于前一层,所以梯度的 All-Reduce 和后向过程同时计算,以进一步缓解网络瓶颈。
- 用optimizer更新参数:每个节点都得到了平均梯度,原参数也是相同的,这样各个 GPU 中的模型参数保持同步 。
ZeRO
数据并行因其易用性,得到了最为广泛的应用。然而,数据并行会产生大量冗余 Model States 的空间占用。ZeRO 的本质,是在数据并行的基础上,对冗余空间占用进行深度优化。
Model State的组成:
- Optimizer States:
Optimizer States是 Optimizer 在进行梯度更新时所需要用到的数据,例如 SGD 中的Momentum以及使用混合精度训练时的Float32 Master Parameters。 - Gradient: 在反向传播后所产生的梯度信息,其决定了参数的更新方向。
- Model Parameter: 模型参数,也就是我们在整个过程中通过数据“学习”的信息。
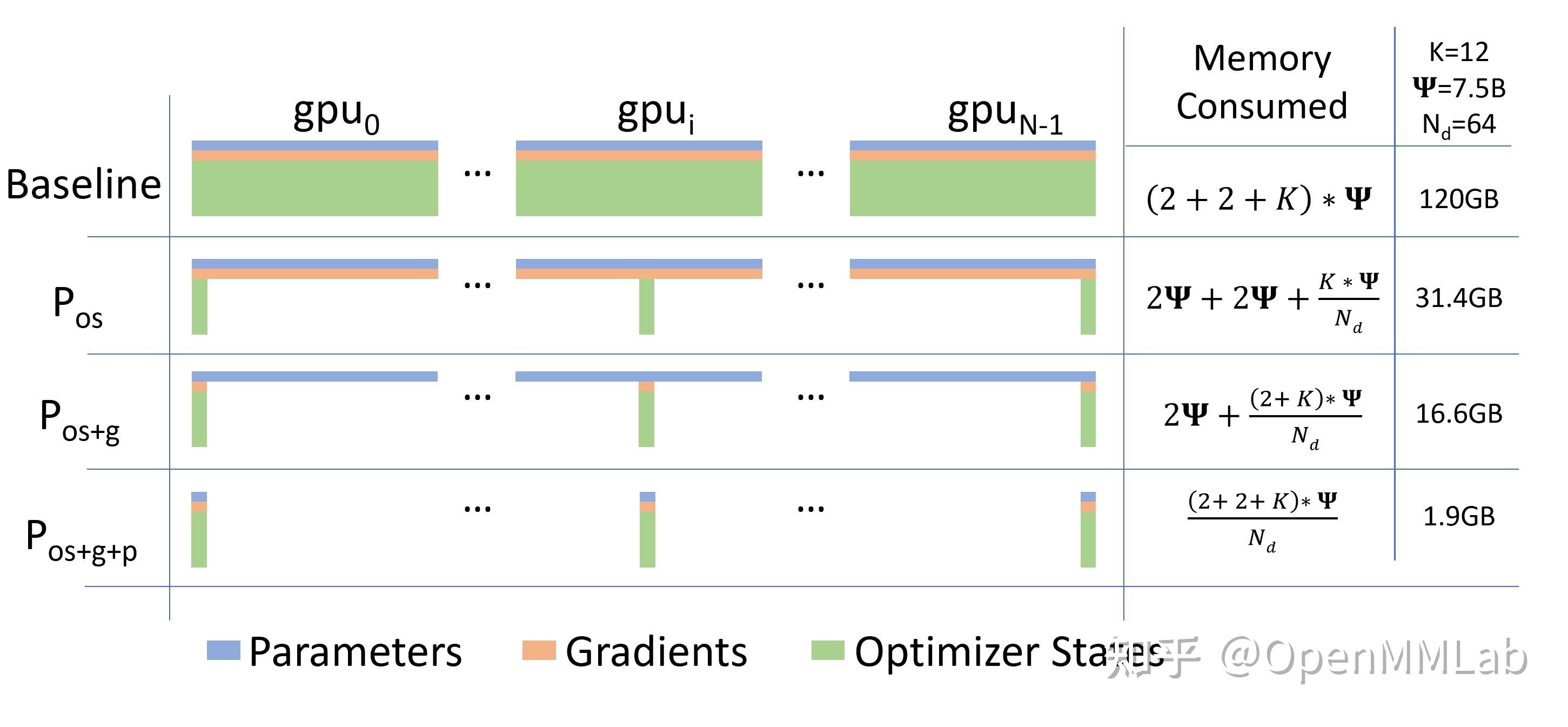
在传统数据并行下,每个进程都使用同样参数来进行训练。每个进程也会持有对Optimizer States的完整拷贝,同样占用了大量显存。在混合精度场景下,以参数量为Ψ的模型和Adam
optimzier为例,Adam需要保存: -
Float16的参数和梯度的备份。这两项分别消耗了2Ψ和2Ψ
Bytes内存;(1 Float16 = 2 Bytes) -
Float32的参数,Momentum,Variance备份,对应到
3 份4Ψ的内存占用。(1 Float32 = 4 Bytes)
最终需要2Ψ + 2Ψ + KΨ = 16Ψ bytes的显存。一个7.5B参数量的模型,就需要至少
120 GB
的显存空间才能装下这些Model States。当数据并行时,这些重复的Model States会在N个GPU上复制N份[1]。
有三个级别的ZeRO:
ZeRO-1
Optimizer
在进行梯度更新时,会使用参数与Optimizer States计算新的参数。而在正向或反向传播中,Optimizer States并不会参与其中的计算。
(算完反向传播梯度就不用关心每个GPU数据不同问题了,梯度已经统一了)因此,我们完全可以让每个进程只持有一小段Optimizer States,利用这一小段Optimizer States更新完与之对应的一小段参数后,再把各个小段拼起来合为完整的模型参数。ZeRO-1
中正是这么做的:
- forward过程由每个rank的GPU独自完整的完成,然后进行backward过程。在backward过程中,梯度通过allReduce进行同步。
- Optimizer state 使用贪心策略基于参数量进行分片,以此确保每个rank几乎拥有相同大小的优化器内存。
- 每个rank只负责更新当前优化器分片的部分,由于每个rank只有分片的优化器state,所以当前rank忽略其余的state。
- 在更新过后,通过广播或者allGather的方式确保所有的rank都收到最新更新过后的模型参数。
ZeRO-1 非常适合使用类似Adam进行优化的模型训练,因为Adam拥有额外的参数m(momentum)与v(variance),特别是FP16混合精度训练。ZeRO-1 不适合使用SGD类似的优化器进行模型训练,因为SGD只有较少的参数内存,并且由于需要更新模型参数,导致额外的通讯成本。ZeRO-1只是解决了Optimizer state的冗余。
ZeRO-2
ZeRO-1将Optimizer States分小段储存在了多个进程中,所以在计算时,这一小段的Optimizer States也只需要得到进程所需的对应一小段Gradient就可以。遵循这种原理,和Optimizer States一样,ZeRO-2也将Gradient进行了切片:
在一个Layer的Gradient都被计算出来后: -
Gradient通过AllReduce进行聚合。 (类似于DDP)
-
聚合后的梯度只会被某一个进程用来更新参数,因此其它进程上的这段Gradient不再被需要,可以立马释放掉。(按需保留)
这样就在ZeRO-1的基础上实现了对Gradient的切分。
ZeRO-3
ZeRO-3
通过对Optimizer States,Gradient和Model Parameter三方面的分割,从而使所有进程共同协作,只储存一份完整
Model
States。其核心思路就是精细化通讯,按照计算需求做到参数的收集和释放。
宏观做法
初始化:一个模型由多个
Submodule组成。在初始化时,ZeRO-3 会将每个Submodule Parameter Tensor下的数据按照 GPU 的数量,分摊切割成多个小ds_tensor储存在在不同 GPU 进程中。因为ds_tensor可以共同组合出完整数据,所以原始param下的数据变为冗余信息,会被释放掉。训练中:在训练过程中,ZeRO-3 会按照
Submodule的计算需求进行参数的收集和释放: 在当前Submodule正向/反向传播计算前,ZeRO-3 通过All-gather拿到分摊储存在不同进程中的ds_tensor,重建原始的param。重建之后的参数就可以参与计算。计算后:在当前
Submodule正向/反向传播计算后,param下的数据并没有发生变更,与 ds_tensor 相同,造成了冗余。因此,param会再次被释放。
经过 ZeRO-3, 一套完整的 model states 就被分布式储存在了多个 GPU 进程中。通过按照计算需求的数据收集和释放,实现储存空间有限的情况下超大规模模型的训练。
代码详解
TBC Optimizer state sharding (ZeRO) - 知乎 (zhihu.com)
HDFS
计算流程
Pytorch 的FSDP是一种数据并行的训练方法,它实际上就是ZeRO-3.

这里,All-Reduce操作被分为All-gather和Reduce-Scatter操作
