Hadoop
Hadoop
Hadoop = HDFS + MapReduce
HDFS为海量数据提供了存储,而MapReduce为海量数据提供了计算框架。
基本概念
HDFS
- NameNode :是Master节点(主节点),可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
- DataNode : 是Slave节点(从节点),是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
- Client : 切分文件;访问HDFS;与NameNode交互,获得文件位置信息;与DataNode交互,读取和写入数据。
Block:Block是HDFS中的基本读写单元;HDFS中的文件都是被切割为block(块)进行存储的;这些块被复制到多个DataNode中;块的大小(通常为64MB)和复制的块数量在创建文件时由Client决定。
写入流程
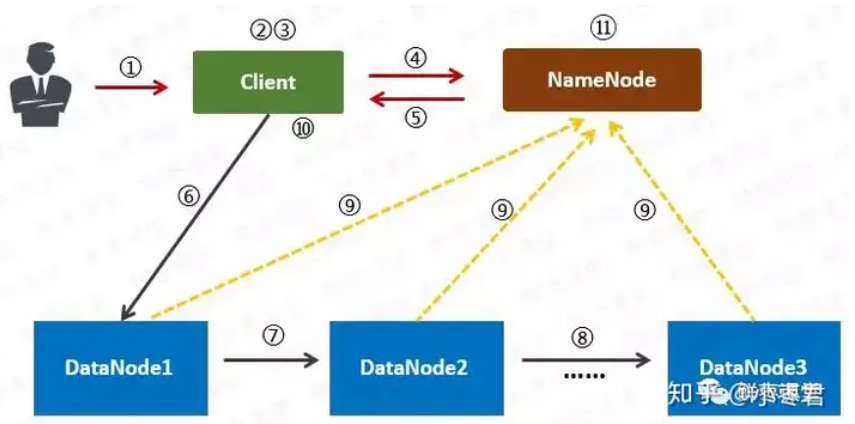
1 用户向Client(客户机)提出请求。例如,需要写入200MB的数据。
2 Client制定计划:将数据按照64MB为块,进行切割;所有的块都保存三份。
3 Client将大文件切分成块(block)。
4 针对第一个块,Client告诉NameNode(主控节点),请帮助我,将64MB的块复制三份。
5 NameNode告诉Client三个DataNode(数据节点)的地址,并且将它们根据到Client的距离,进行了排序。
6 Client把数据和清单发给第一个DataNode。
7 第一个DataNode将数据复制给第二个DataNode。
8 第二个DataNode将数据复制给第三个DataNode。
9 如果某一个块的所有数据都已写入,就会向NameNode反馈已完成。
10 对第二个Block,也进行相同的操作。
11 所有Block都完成后,关闭文件。NameNode会将数据持久化到磁盘上。
读出流程
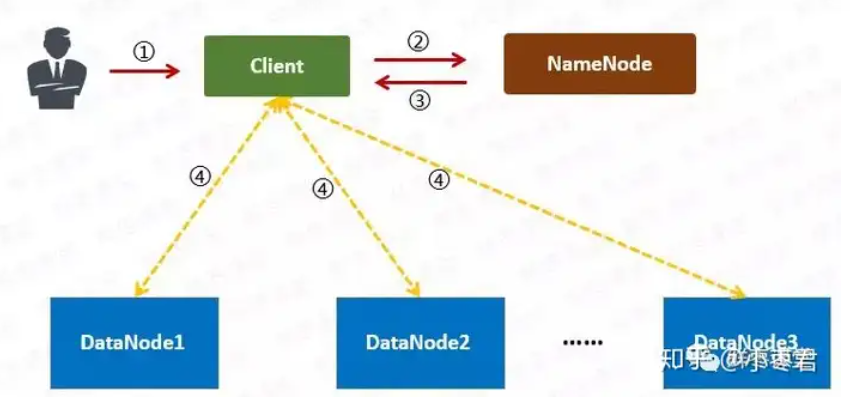
1 用户向Client提出读取请求。
2 Client向NameNode请求这个文件的所有信息。
3 NameNode将给Client这个文件的块列表,以及存储各个块的数据节点清单(按照和客户端的距离排序)。
4 Client从距离最近的数据节点下载所需的块。
MapReduce
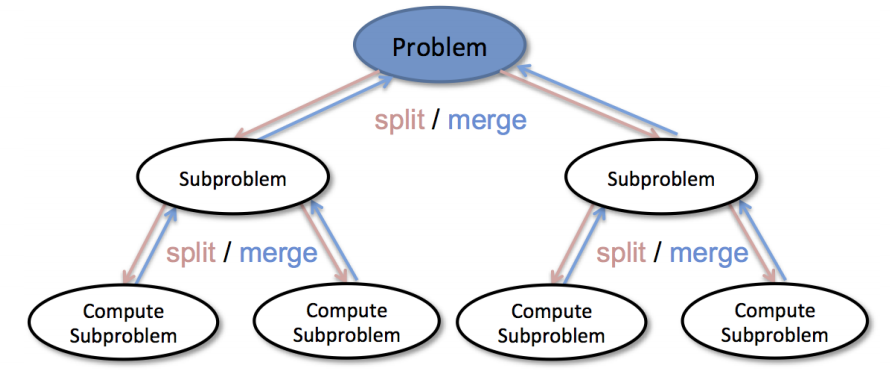
- Map映射: 把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分
- Reduce归约 : 把前面若干a 个Map的输出汇总到一起并输出。
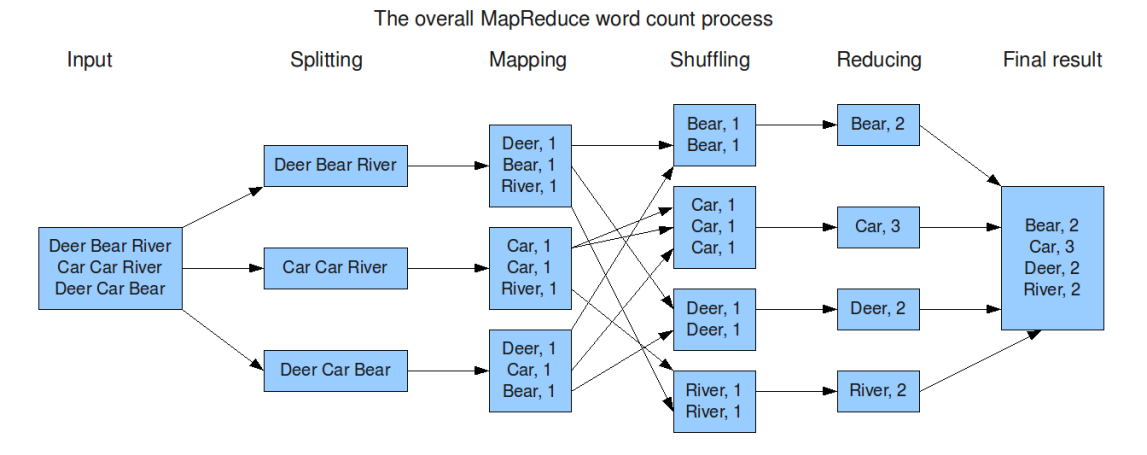
- JobTRacker: 用于调度和管理其它的TaskTracker, 可以运行于集群中任一台计算机上。
- TaskTracker: 负责执行任务,必须运行于 DataNode 上。
YARN
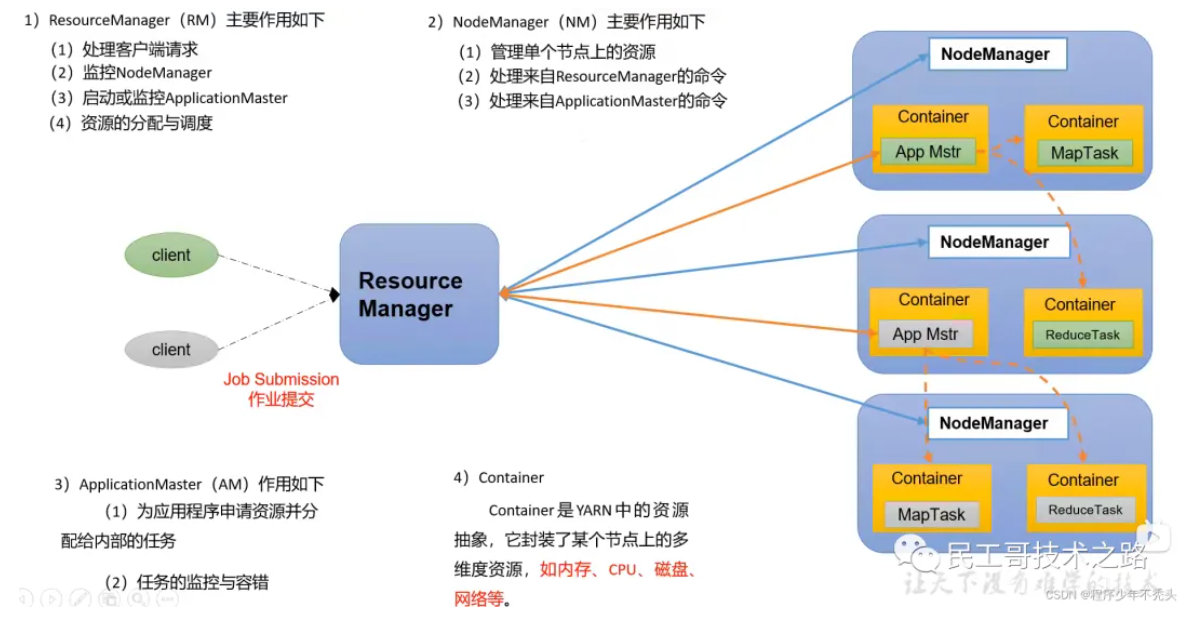
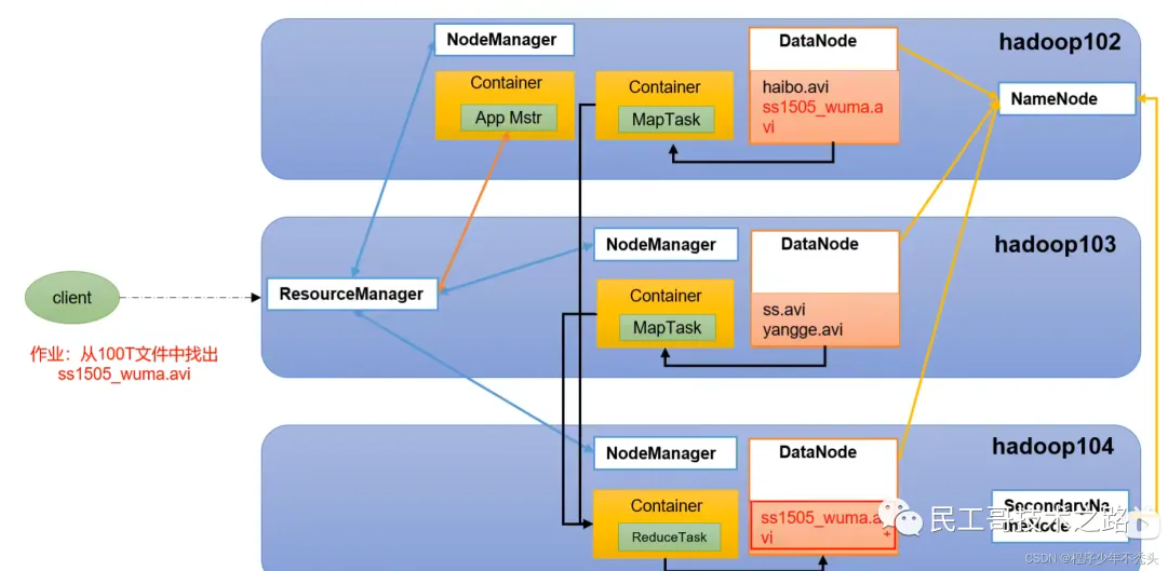
ResourceManager(RM):整个集群资源(内存、CPU等)的管理者
NodeManager(NM):单个节点服务器的管理者
ApplicationMaster(AM):单个任务运行的负责人
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源(内存、CPU、磁盘、网络)
注意
- 客户端可以有多个
- 集群上可以运行多个 ApplicationMaster
- 每个 NodeManager 上可以有多个 Container
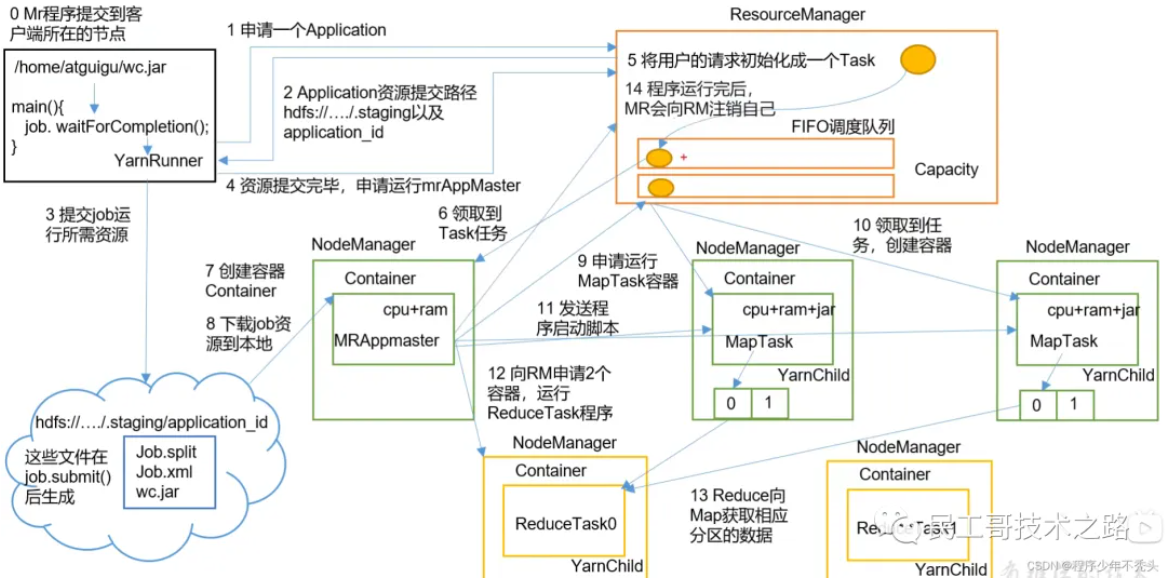
三者关系