LLM
LLM
NLP
Transformer
- self-attention表达式
\[ Softmax(\frac{QK^T}{\sqrt{d_k}})V \]
why scaling
\(QK^t\)相乘会让数值变大,scaling 后进行softmax可以使得输入的数据的分布变得更好,避免数据进入softmax敏感区间,防止梯度消失,让模型能够更容易训练。
可以不除以\(\sqrt{d_k}\)吗 ?
可以,只要有别的方法可以缓解梯度消失即可
self-attention一定要这样表达吗
不一定,只要可以建模相关性就可以。这样表示的优点:高速计算(矩阵乘法);表达能力强(query可以主动去关注到其他的key并在value上进行强化,并且忽略不相关的其他部分),模型容量够(引入了project_q/k/v,att_out,多头)。
为什么transformer用Layer Norm?有什么用?
任何norm的意义都是为了让使用norm的网络的输入的数据分布变得更好,也就是转换为标准正态分布,避免数值进入敏感度区间,以减缓梯度消失,从而更容易训练。当然,这也意味着舍弃了除此维度之外其他维度的其他信息。layer norm舍弃了batch维度信息; batch Norm舍弃了layer维度信息。
为什么不用BN
BN广泛应用于CV,针对同一特征,以跨样本的方式开展归一化,也就是对不同样本的同一channel间的所有像素值进行归一化,因此不会破坏不同样本同一特征之间的关系,毕竟“减均值,除标准差”只是一个平移加缩放的线性操作。在“身高体重”的例子中,这就意味着“归一化前是高个儿的归一化后仍然是高个儿,归一化前胖的归一化后也不会变瘦”。这一性质进而决定了经过归一化操作后,样本之间仍然具有可比较性。但是,同一样本特征与特征之间的不再具有可比较性,也就是上一个问题中我所说的“舍弃了除此维度之外其他维度的其他信息”。
但是在NLP中对不同样本同一特征的信息进行归一化没有意义,而且不能舍弃同一个样本的不同维度的信息。
Bert为什么要搞一个position embedding?
self-attention无法表达位置信息,用三角函数避免句子过长时位置编码太大。
Bert为什么三个embedding可以相加?
在实际场景中,叠加是一个更为常态的操作。比如声音、图像等信号。一个时序的波可以用多个不同频率的正弦波叠加来表示。只要叠加的波的频率不同,我们就可以通过傅里叶变换进行逆向转换。
一串文本也可以看作是一些时序信号,也可以有很多信号进行叠加,只要频率不同,都可以在后面的复杂神经网络中得到解耦(但也不一定真的要得到解耦)。在BERT这个设定中,token,segment,position明显可以对应三种非常不同的频率。
transformer为什么要用三个不一样的QKV?
增强网络的表达能力。
为什么要多头?举例说明多头相比单头注意力的优势?
增强网络的表达能力。不同的头关注不同信息。
假设有一个句子"the cat, which is black, sat on the mat"。在处理"sat"这个词时,一个头可能会更注"cat",因为"cat"是"sat"的主语;另一个头可能会更关注"on the mat",因为这是"sat"的宾语;还有一个头可能会关注"which is black",因为这是对"cat"的修饰。
经过多头之后,我们还需要att_out线性层来做线性变换,以自动决定(通过训练)对每个头的输出赋予多大的权重,从而在最终的输出中强调一些头的信息,而忽视其他头的信息。
为什么Bert中要用WordPiece/BPE这样的subword Token?
避免OOV(Out Of Vocabulary),也就是词汇表外的词。在NLP中,通常会预先构建一个词汇表,包含所有模型能够识别的词。然而,总会有一些词没有出现在预先构建的词汇表中,这些词就是 OOV。
传统的处理方式往往是将这些 OOV 映射到一个特殊的符号,如
<UNK>,但这种方式无法充分利用 OOV 中的信息。例如,对于词汇表中没有的词 "unhappiness",如果直接映射为<UNK>,则模型就无法理解它的含义。WordPiece/Byte Pair Encoding (BPE) 等基于子词的分词方法提供了一种解决 OOV 问题的方式。现在更多的语言大模型选择基于BPE的方式,只不过BERT时代更多还是WordPiece。BPE 通过将词分解为更小的单元(子词或字符),可以有效地处理词汇表外的词。对于上面的 "unhappiness" 例子,即使 "unhappiness" 本身不在词汇表中,但是它可以被分解为 "un"、"happiness" 等子词,而这些子词可能在词汇表中。这样,模型就可以通过这些子词来理解 "unhappiness" 的含义。
另一方面就是,BPE本身的语义粒度也很合适,一个token不会太大,也不会小到损失连接信息(如一个字母)。
Bert中为什么要在开头加个[CLS]?
用[cls]学习整个句子的表示
不用[CLS]的语义输出,有其他方式可以代替吗?
这个问题还是考察到了[CLS]的核心内涵,也就是如何获得整个sentence的语义表示。既然不让使用特意训好的[CLS],那我们就从每个token得到的embedding入手,把所有的token弄到一起。
很直观的思路,就是对BERT的所有输出词向量(忽略[CLS]和[SEP])应用MaxPooling和AvgPooling,然后将得到的两个向量拼接起来,作为整个序列的表示。这样做的话可以同时保留序列中最显著的特征(通过MaxPooling)和整体的,均衡的特征(通过AvgPooling)。
Bert中有哪些地方用到了mask?
预训练任务Masked Language Model (MLM):
主要的思想是,把输入的其中一部分词汇随机掩盖,模型的目标是预测这些掩盖词汇。这种训练方式使得每个位置的BERT都能学习到其上下文的信息。
self-attention的计算:
不同样本的seq_len不一样。但是由于输出的seq_len需要一致,所以需要通过补padding来对齐。而在attention中我们不希望一个token去注意到这些padding的部分,attention中的mask就是来处理掉这些无效的信息的。
具体来说就是在softmax前每个都设为-inf,然后过完softmax后"padding"部分的权重就会接近于零,query token就不会分配注意力权重了。
下游任务的decoder:
在做next token prediction的时候,模型是根据前面已有的tokens来做的,也就是看不到未来的tokens的信息。而在我们训练的过程中,通常采用teacher forcing的策略,也就是我们当然会把完整的标签喂给模型,但是由于在一个一个生成next token的过程中,模型应该是一个一个往外“蹦“字的过程(想想chatgpt回复你的样子)所以我们会遮盖掉seqence中当前位置之后信息,以防止模型利用未来信息,也就是信息泄露。mask掉后模型的注意力只会集中在此前的序列上。
Bert中self attention 计算复杂度如何?
\(O(d_L^2)\),因为输入的序列的每一个token都要对这个序列上的所有token去求一个attention score。
有什么技术降低复杂度提升输入长度的?
比如Sparse Attention,放弃对全文的关注,只关心局部的语义组合,相当于self-attention上又加了一些mask,这样的话就可以降低复杂度,而且下游任务的语义关联性的体现往往是局部/稀疏的。
为什么以前char level/subword level的NLP模型表现一般都比较差,但是到了bert这里就比较好?
还是归功于Transformers,因为对于字符级别(char-level)或者子词级别(subword-level)的NLP模型,挑战在于需要模型能够理解字符或者子词组合起来形成词语和句子的语义,这对模型的能力有很高的要求。
然而,以前NLP模型没办法做到很深,两层lstm基本就到极限了,非线性成长路线过分陡峭,所以增加网络容量的时候,降低了泛化能力。
Bert降低了输入的复杂度,提升了模型的复杂度。模型多层产生的非线性增长平滑,可以加大网络容量,同时增强容量和泛化能力。
Bert为什么要使用warmup的学习率trick
主要是考虑到训练的初始阶段params更新比较大,可能会使模型陷入local minima或者overfitting。
warmup就是把lr从一个较小的值线性增大到预设,以减缓参数震荡,让训练变得比较smooth,当模型参数量上来后这种策略变得更重要了。
为什么说GPT是单向的Bert是双向的?
这也是decoder-only和encoder-only的区别。
decoder-only架构的生成模型在输出的时候只能看到当前位置前的tokens,也就是屏蔽了序列后面的位置,以适配NTP任务。
encoder-only架构的编码模型在输出的时候可以利用前后位置的tokens,以适配MLM任务。
具体的做法是self-attention加不加casual mask,也就是遮不遮住序列后面的内容。
Bert如何处理一词多义?
一词多义指的是在不同句子中token有不同的含义。
这正是self-attention解决的,搭配上MLM的任务,就可以让每个token会注意到上下文的其他token来得到自己的embedding。
Bert中的transformer和原生的transformer有什么区别?
其实很多,如果我们只讨论模型架构,也就是对比Attention is All You Need的encoder和BERT的话,最重点的区别在于位置编码。
原生的transformer是最经典的Sinusoidal绝对位置编码。
而BERT中变成了可以学习的参数,也就是可学习位置编码。
四种Norm
Batch Norm:把每个Batch中,每句话的相同位置的字向量看成一组做归一化。
Layer Norm:在每一个句子中进行归一化。
Instance Norm:每一个字的字向量的看成一组做归一化。
Group Norm:把每句话的每几个字的字向量看成一组做归一化。
Batch Normalization(Batch Norm): 缺点:在处理序列数据(如文本)时,Batch Norm可能不会表现得很好,因为序列数据通常长度不一,并且一次训练的Batch中的句子的长度可能会有很大的差异;此外,Batch Norm对于Batch大小也非常敏感。对于较小的Batch大小,Batch Norm可能会表现得不好,因为每个Batch的统计特性可能会有较大的波动。
Layer Normalization(Layer Norm): 优点:Layer Norm是对每个样本进行归一化,因此它对Batch大小不敏感,这使得它在处理序列数据时表现得更好;另外,Layer Norm在处理不同长度的序列时也更为灵活。
Instance Normalization(Instance Norm): 优点:Instance Norm是对每个样本的每个特征进行归一化,因此它可以捕捉到更多的细节信息。Instance Norm在某些任务,如风格迁移,中表现得很好,因为在这些任务中,细节信息很重要。 缺点:Instance Norm可能会过度强调细节信息,忽视了更宏观的信息。此外,Instance Norm的计算成本相比Batch Norm和Layer Norm更高。
Group Normalization(Group Norm): 优点:Group Norm是Batch Norm和Instance Norm的折中方案,它在Batch的一个子集(即组)上进行归一化。这使得Group Norm既可以捕捉到Batch的统计特性,又可以捕捉到样本的细节信息。此外,Group Norm对Batch大小也不敏感。 缺点:Group Norm的性能取决于组的大小,需要通过实验来确定最优的组大小。此外,Group Norm的计算成本也比Batch Norm和Layer Norm更高。
大模型算法
并行计算
并行化指的是拆分任务并将它们分布到多个处理器或设备(如gpu)上,以便它们可以同时完成。
Data Parallenlism
数据并行性将训练数据分成多个分片(partition),并将其分布到不同的节点上。 每个节点首先用自己的局部数据训练自己的子模型,然后与其他节点通信,以一定的间隔将结果组合在一起,从而得到全局模型。 最大的缺点是,在向后传递期间,您必须将整个梯度传递给所有其他gpu。它还在所有工作线程中复制模型和优化器,这是相当低内存效率的。
Tensor Parallelism
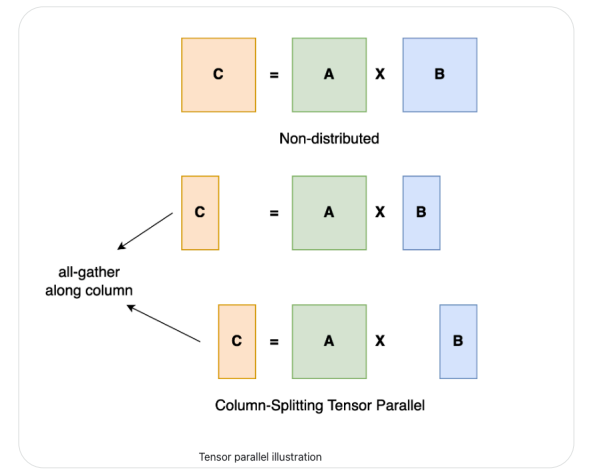
张量并行将大型矩阵乘法划分为较小的子矩阵计算,然后使用多个gpu同时执行。
然而,缺点是它在每次前向和后向传播中引入了额外的激活通信,因此需要高通信带宽才能高效
Pipeline parallelism and model parallelism
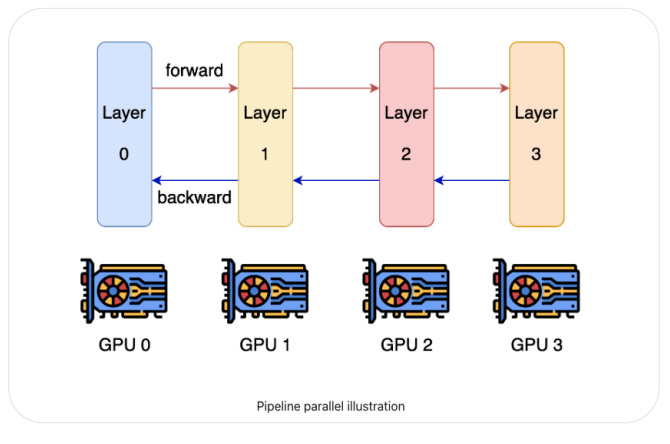 管道并行通过将模型的层划分为可以并行处理的阶段来提高深度学习训练的内存和计算效率。这有助于显著提高总体吞吐量速度,同时增加最小的通信开销。你可以把管道并行看作是“层间并行”(张量并行可以看作是“层内并行”)。
管道并行通过将模型的层划分为可以并行处理的阶段来提高深度学习训练的内存和计算效率。这有助于显著提高总体吞吐量速度,同时增加最小的通信开销。你可以把管道并行看作是“层间并行”(张量并行可以看作是“层内并行”)。与管道并行类似,模型并行是指在gpu之间分割模型并为每个模型使用相同的数据;所以每个GPU只处理模型的一部分,而不是数据的一部分。管道和模型并行的缺点是它不能无限扩展,因为管道并行的程度受模型深度的限制。
PTD-P
combines pipeline, tensor, and data parallelism
Gradient accumulation
在一次对所有累积的梯度执行一个权重更新步骤之前,将多个批次的梯度相加。
这种方法减少了之间的通信开销,gpu通过允许它们独立地处理自己的本地批数据,直到它们再次相互同步,在为单个优化步骤积累足够的梯度之后。
Asynchronous stochastic gradient descent optimization
- 从参数服务器获取处理当前小批量所需的模型的最新参数。
- 我们根据这些参数计算损失的梯度.
- 这些梯度被发送回参数服务器,然后参数服务器相应地更新模型。
Micro-batching
将 small mini-batches合并成大批,这样在反向传播操作期间,可以在更短的时间内处理更多的批,并且在设备之间使用更少的同步点。
数据集预处理
- Data Sampling
某些数据组件可以被上采样以获得更平衡的数据分布。一些研究对低质量的数据集进行了降采样,如未过滤的网络爬虫数据。其他研究根据模型目标对特定领域的数据进行采样。
还有一些先进的方法可以过滤高质量的数据,例如将训练好的分类器模型应用到数据集上。例如,Meta AI的模型Galactica是专门为科学而建立的,特别是存储、组合和推理科学知识。
- Data cleaning
删除样板文本和HTML代码或标记,修复拼写错误,处理跨域单应词,删除有偏见、有害的言论。
有的项目,这些技术并没有被使用,因为模型应该看到真实世界的公平表示,并学习处理拼写错误和毒性作为模型能力的一部分。
- Non-standard textual components handling
非标准文本组件转换为文本,例如,将表情符号雪花转换为对应的文本“snowflake”。
- Data deduplication
擅长重复数据
- Downstream task data removal
在训练集中删除测试集中也存在的数据
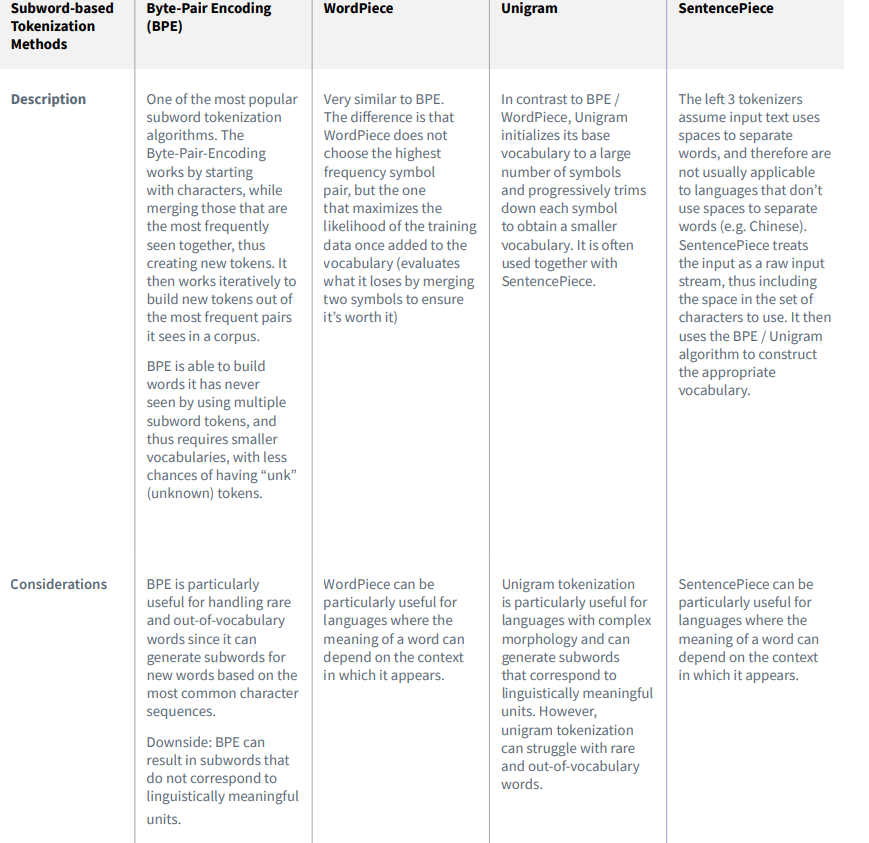
Tokenization
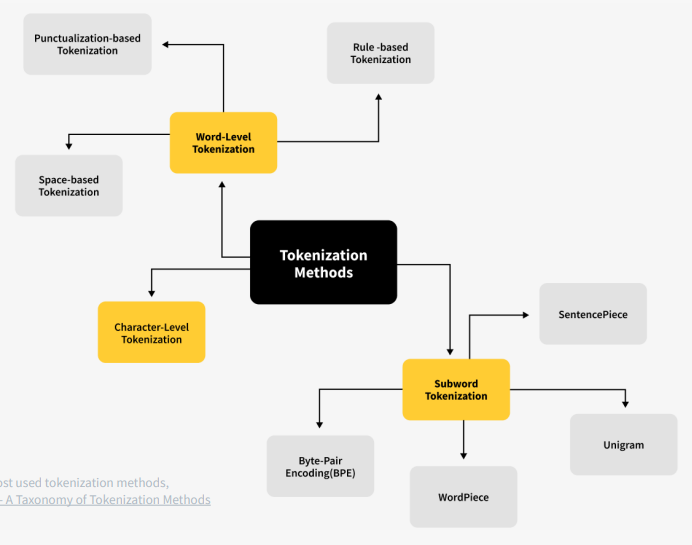
将文本字符串编码为transformer可读的token ID整数。
Most state-of-the-art LLMs use subword-based tokenizers like byte-pair encoding (BPE) as opposed to word-based approaches.
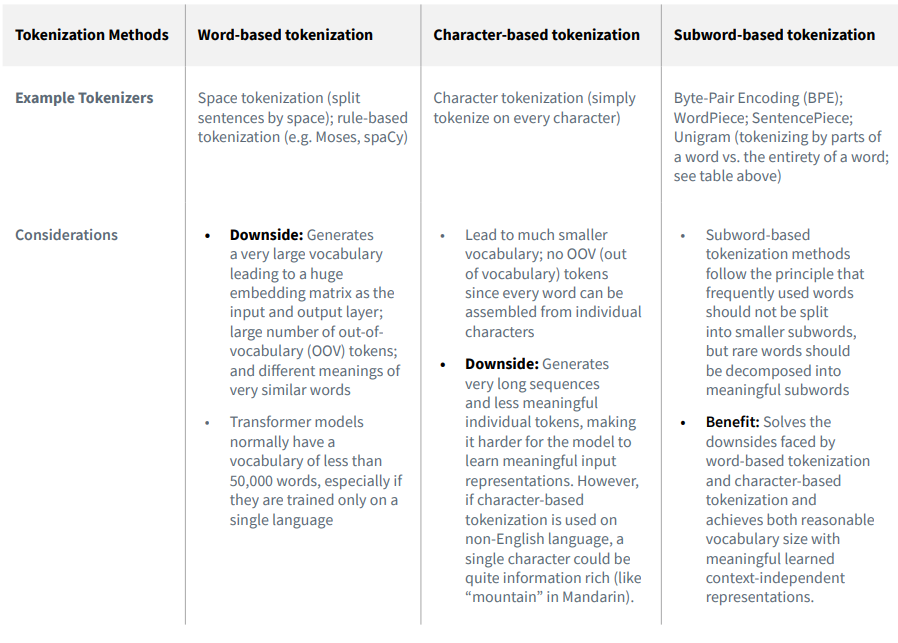
subword-based methods
Pre-Train
Supervised fine-tuning (SFT)
人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法_lora ptuningv2-CSDN博客
lora:

人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法_lora ptuningv2-CSDN博客