DHT-Relation Work
Relation work of DHT
Edgeformers
EDGEFORMERS: G RAPH-E MPOWERED TRANSFORMERS FOR REPRESENTATION L EARNING ON T EXTUALE DGE NETWORKS
Background
Edge-aware GNNs:
studies assume the information carried by edges can be directly described as an attribute vector.
- This assumption holds well when edge features are categorical
- cannot fully capture contextualized text semantic
PLM-GNN
text information is first encoded by a PLM and then aggregated by a GNN
- such architectures process text and graph signals one after the other, and fail to simultaneously model the deep interactions
GNN-nested PLM
inject network information into the text encoding process
- cannot be easily adapted to handle text-rich edges
Proposed method
- we conduct edge representation learning by jointly considering text and network information via a Transformer-based architecture (Edgeformer-E).
- perform node representation learning using the edge representation learning module as building blocks (Edgeformer-N)

Network-aware Edge Text Encoding with Virtual Node Tokens
Given an edge \(e_{ij}=(v_i,v_j)\)
Use a transformer to deal with text
introduce two virtual node tokens to represent $ v_i$ and \(v_j\) to transformer
$ v_i$ 和 \(v_j\) 是连接边两个node的embedding]

TEXT-A WARE NODE REPRESENTATION LEARNING (EDGEFORMER-N)
node-Aggregating Edge Representations

Enhancing Edge Representations with the Node’s Local Network Structure
add one more virtual node in edge learning :获取与边节点连接的邻居边的信息
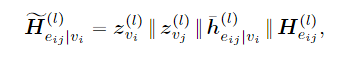
邻居边的embedding经过一个新tranformer,获取
GRATIS
Paper:GRATIS: Deep Learning Graph Representation with Task-specifific Topology and Multi-dimensional Edge Features
总结:计算一个全局representation-X,X经过MLP和reshape、softmax等操作变成和邻接矩阵大小相同的权重矩阵,然后得到一个edge出现的概率矩阵,概率大于一定阈值就补全边。
edge用向量表示而不是一个一维数(一维权重)。
Methology


Backbone
反正就是各种方法得到一个全局表示X
Graph Definition
采用图原来的点和边
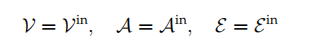
Task-specific Topology Prediction
用X计算出一个概率矩阵
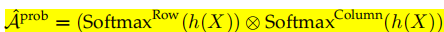
h(x)为mlp
如果概率大于某个阈值,增加新边
Multi-dimensional Edge Feature Generation
根据边两端的节点计算边
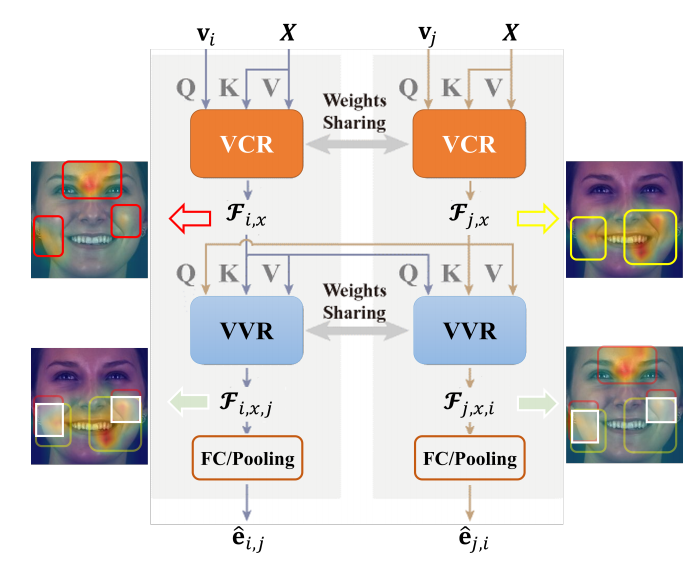
VCR

VVR

fifinally employ either a pooling layer or a fully-connected layer, to flatten \(F_{i,x,j}\) and \(F_{ *j,x,i*}\)
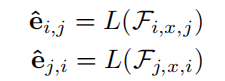
SURGE
Paper: Knowledge-Consistent Dialogue Generation with Knowledge Graphs
总结:在KG大图中检索与文本相关的子图,用GCN计算node representation,用ENGNN计算 edge representation。然后用在后面的任务