GeneralReading
MKR,RKGE,HAGERec,entity2rec,HAKG
MKR
Framework

The framework of MKR is illustrated in Figure 1a.
MKR consists of three main components: recommendation module, KGE module, and cross&compress units.
The recommendation module on the left takes a user and an item as input, and uses a multi-layer perceptron (MLP) and cross&compress units to extract short and dense features for the user and the item, respectively. The extracted features are then fed into another MLP together to output the predicted probability.
Similar to the left part, the KGE module in the right part also uses multiple layers to extract features from the head and relation of a knowledge triple, and outputs the representation of the predicted tail under the supervision of a score function f and the real tail.
The recommendation module and the KGE module are bridged by specially designed cross&compress units. The proposed unit can automatically learn high-order feature interactions of items in recommender systems and entities in the knowledge graph.
u: MLP to update
v: cross&compress units
r: MLP to update
h: cross&compress units
Loss function

RKGE
RKGE first automatically mines all qualified paths between entity pairs from the KG, which are then encoded via a batch of recurrent networks, with each path modeled by a single recurrent network.
It then employs a pooling operation to discriminate the importance of different paths for characterizing user preferences towards items.
framework
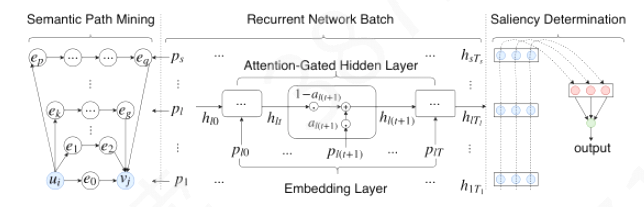
Semantic Path Mining
Strategy
- We only consider user-to-item paths \(P(u_i,v_j)\) that connect \(u, i\) with all her rated items.
- We enumerate paths with a length constraint.
Encode path
use recurrent networks
Embedding layer
generate the embedding of entities
Attention-Gated Hidden Layer
就是一个RNN网络的变种
HAGERec
Framework

four components:
Flatten and embedding layer: flatten complex high-order relations and embedding the entities and relations as vectors.
GCN learning layer: uses GCN model to propagate and update user’s and item’s embedding via a bi-directional entity propagation strategy
Interaction signals unit: preserves interaction signals structure of an entity and its neighbor network to give a more complete picture for user’s and item’s representation.
Prediction layer: utilizes the user’s and item’s aggregated representation with prediction-level attention to output the predicted score.
Flatten and embedding

flatten high-order connection to the path: \(u\rightarrow^{r1}v\rightarrow^{r2}e_{u1}\rightarrow^{r3}e_{v3}\)
embedding: initialized embedding vectors.
GCN learning unit
user and item use the same propagation and aggregate strategy.

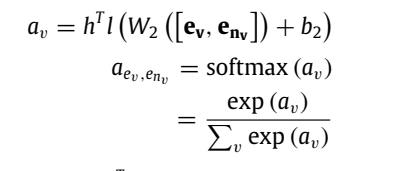
\(h^T, W, b\): learned parameters
neighbor sample(only get fixed number neighbor): \(\alpha_{e_v,e_{nv}}\) would be regarded as the similarity of each neighbor entity and central entity. Through this evidence, those neighbors with lower similarity would be filtered.
Interaction signals unit
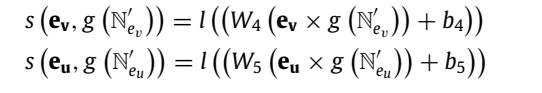
区别:上面是相加,下面事相乘
so GCN unit + interaction unit =
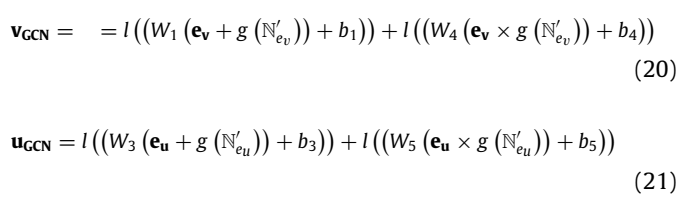
Predict
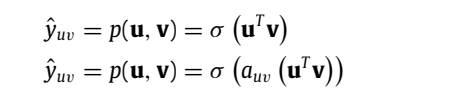
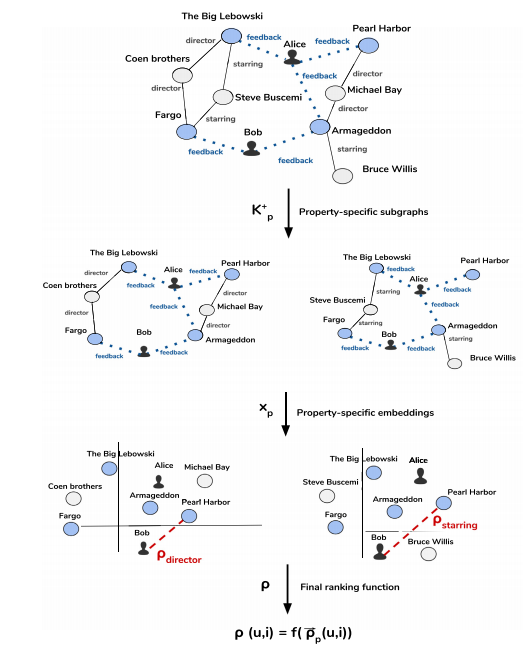
Entity2rec
Framework
node2vec

将图用random walk转化为word格式,用词袋模型计算vector。
Property-specific knowledge graph embedding
在node2vec基础上加上relation embedding,基于p子图在p空间上优化node vector
maximize the dot product between vectors of the same neighborhood

Ze-negative sampling
N(e): neighbor of entity
subgraph
Collaborative-content subgraphs
只保留单一relation,但连接性很差,对random walk效果不好

所有子图可以分成两张类型:feedback子图(user-item图)和其他子图
用下面方法来计算推荐分数:
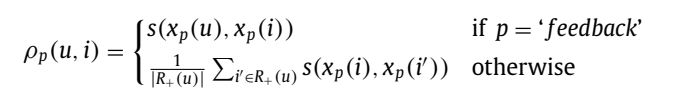
R+(u) denotes a set of items liked by the user u in the past.
s(x): similarity socre
Hybrid subgraphs
\(K_p^+=K_p \cup(u,feedback,i)\)

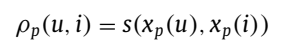
HAKG
总结:抽取u,i子图,进行正常的propagation之后,得到自图中所有entity的embedding,包括user和item。用self-attention提取entity相互影响信息,得到矩阵g(u,i),再用use embedding,item embedding和g(u,i)进行预测,充分利用了子图中的所有信息。
Framework

- Subgraph Construction :it automatically constructs the expressive subgraph that links the user-item pair to represent their connectivity;
- Hierarchical Attentive Subgraph Encoding : the subgraph is further encoded via a hierarchical attentive embedding learning procedure, which first learns embeddings for entities in the subgraph with a layer-wise propagation mechanism, and then attentively aggregates the entity embeddings to derive the holistic subgraph embedding;
- Preference Prediction : with the well-learned embeddings of the user-item pair and their subgraph connectivity, it uses non-linear layers to predict the user’s preference towards the item.
Subgraph Construction
path sampling and then reconstructs the subgraphs by assembling the sampled paths between user-item pairs
path sampling
use random walk get path from u to i and length<=6, uniformly sample K paths
Path Assembling
just assemb the K paths
Hierarchical attentive subgraph encoding
entity embedding learning

Embedding Initialization
- initial
- \(e_h^{(0)}=MLP(e_h \space concatenation \space t_h)\)
Semantics Propagation
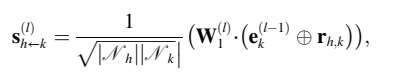
Semantics Aggregation

final entity embedding is \(e_h^{(L)}\)
constitute an entity embedding matrix H(u,i) for the whole subgraph :
\(H_{(u,i)}=[e_1,e_2,\cdots,e_n]\)
sub-graph embedding learning
use self-attention mechanism optimize the entities embeding of subgraph
Than use pooling method to get subgraph embedding
Prediction
