KGCN
.
Background
CF Questions
- sparsity
- cold start
KG Benefits
- The rich semantic relatedness among items in a KG can help explore their latent connections and improve the precision of results;
- The various types of relations in a KG are helpful for extending a user’s interests reasonably and increasing the diversity of recommended items;
- KG connects a user’s historically-liked and recommended items, thereby bringing explainability to recommender systems.
Previous KG Method
Knowledge graph embedding
Example: TransE [1] and TransR [12] assume head + relation = tail, which focus on modeling rigorous semantic relatedness
Problem: KGE methods are more suitable for in-graph applications such as KG completion and link prediction rather than the recommendation system.
Path-base Method
Example: PER, FMG
problem: Labor sensitivity
Ripple Net
problem:
- the importance of relations is weakly characterized in RippleNet, because the relation R can hardly be trained to capture the sense of importance in the quadratic form v ⊤Rh (v and h are embedding vectors of two entities).
- The size of ripple set may go unpredictably with the increase of the size of KG, which incurs heavy computation and storage overhead.
Solution: KGCN
- Propagation and aggregation mechanism.
- Attention mechanism.
- sample a fixed-size neighborhood to control compute cost.
Model
Single layer
Consider a pair(u,v)
Overall of single layer
!!!Propagation only use for updating of item's vector

Propagation

\(N(v)\) is the neighbor set of v
e$ is the embedding of entity(parameter to train)
\(\pi^u_{r_{v,e}}\) is attention weight
\(r_{v,e}\) represent the relation of v and e
Attention


\(g : R^d ×R^d → R\) (e.g., inner product:内积能计算相似度)to compute the score between a user and a relation
\(u\in R\), \(r\in R\) : embedding of user and relation(parameter to train)
\(\pi^u_{r_{v,e}}\)characterizes the importance of relation r to user u. E.g. example, a user may have more interests in the movies that share the same “star" with his historically liked ones, while another user may be more concerned about the “genre" of movies.
!!!!!!!!!!个性化!!!用户对不同关系重视程度不同!!
所以KGCN不用propagation更新用户的原因是否是因为希望user的embedding能专注于提取个性化信息(提高用户和重要relation的相似度),但是这样是否会让user和item没那么好聚类?
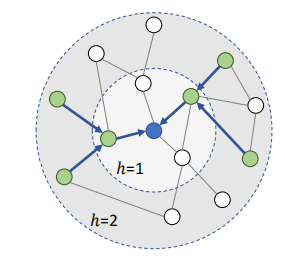
Sample the number of neighbors
limit the neighbor number in K(can be config)

S(v) is also called the (single layer) receptive field of entity v
example K=2:
aggregation

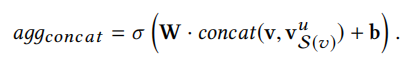

\(\sigma\) is ReLU
Multi layer

First we consider the Receptive-Field:

We first update eneities in M[0] by using propagation and aggregation to get the high-hop neighbor information.
And then gradually narrow it down, and finally focus on v.
Note that we have only one user in one pair, every relations will calculate the score with this user embedding
Predict

Loss function

\(J\) is cross-entropy loss
P is a negative sampling distribution, and \(T_u\) is the number of negative samples for user u. In this paper,