history_v_lists, history_vr_lists: user set (in training set) who
have interacted with the item, and rating score (dict). Similar with
history_u_lists, history_ur_lists but key is item id and value is user
id.
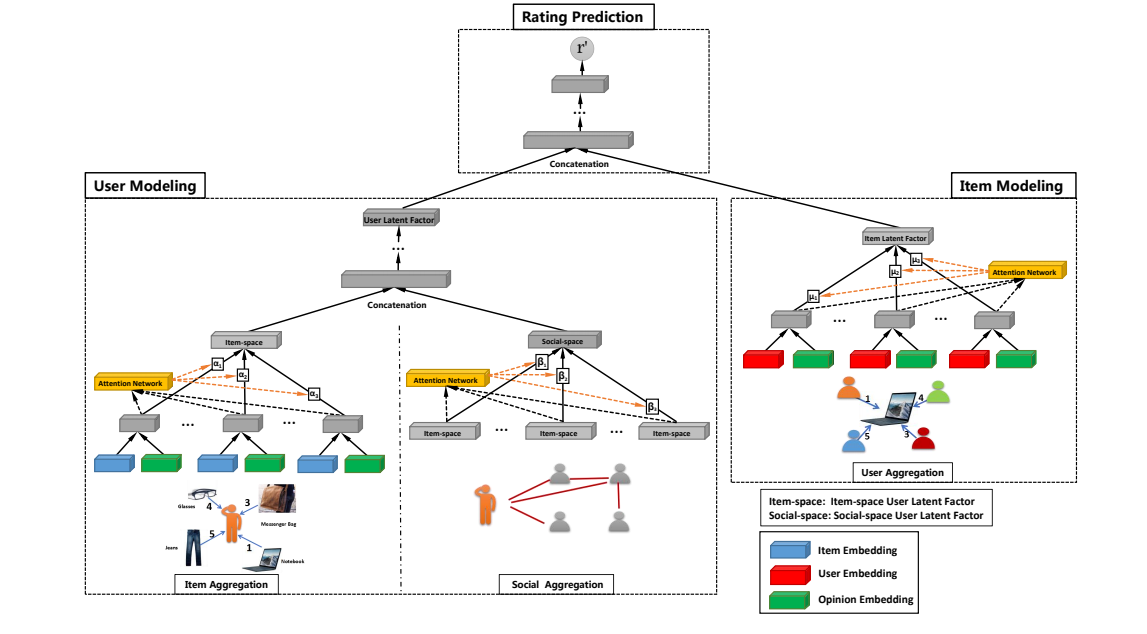
defforward(self, nodes_u, nodes_v): # nodes_u : [128] 128(batchsize) user id # nodes_v : [128] 128(batchsize) item id # self.enc_u is the User Modeling part(including Item Aggregation and Social Aggregation ) # self.enc_v_history is the Item Modeling part(User Aggregation) embeds_u = self.enc_u(nodes_u) embeds_v = self.enc_v_history(nodes_v)
# After aggregation information, forward two layer MLP, and get the Latent vector of user and item x_u = F.relu(self.bn1(self.w_ur1(embeds_u))) x_u = F.dropout(x_u, training=self.training) x_u = self.w_ur2(x_u) x_v = F.relu(self.bn2(self.w_vr1(embeds_v))) x_v = F.dropout(x_v, training=self.training) x_v = self.w_vr2(x_v) # concatenated user vector and item vector, use three layer MLP to predict x_uv = torch.cat((x_u, x_v), 1) x = F.relu(self.bn3(self.w_uv1(x_uv))) x = F.dropout(x, training=self.training) x = F.relu(self.bn4(self.w_uv2(x))) x = F.dropout(x, training=self.training) scores = self.w_uv3(x) return scores.squeeze() defloss(self, nodes_u, nodes_v, labels_list): ...
# to_neighs is a list which element is list recording social neighbor node, and len(list) is batchsize, to_neighs = [] for node in nodes: to_neighs.append(self.social_adj_lists[int(node)])
# Social aggregation neigh_feats = self.aggregator.forward(nodes, to_neighs) # user-user network
# Item aggregation self_feats = self.features(torch.LongTensor(nodes.cpu().numpy())).to(self.device) self_feats = self_feats.t() # self-connection could be considered. # Concatenate Item Aggregation and Social Aggregation, and through one layer MLP combined = torch.cat([self_feats, neigh_feats], dim=1) combined = F.relu(self.linear1(combined))
self.features = features self.social_adj_lists = social_adj_lists self.aggregator = aggregator if base_model != None: self.base_model = base_model self.embed_dim = embed_dim self.device = cuda self.linear1 = nn.Linear(2 * self.embed_dim, self.embed_dim) #
defforward(self, nodes):
# to_neighs is a list which element is list recording social neighbor node, and len(list) is batchsize, to_neighs = [] for node in nodes: to_neighs.append(self.social_adj_lists[int(node)])
# Social aggregation self_feats = self.features(torch.LongTensor(nodes.cpu().numpy())).to(self.device) self_feats = self_feats.t() # self-connection could be considered. # Concatenate Item Aggregation and Social Aggregation, and through one layer MLP combined = torch.cat([self_feats, neigh_feats], dim=1) combined = F.relu(self.linear1(combined))
#get nodes(batch) neighbors #tmp_history_uv is a list which len is 128,while it's element is also a list meaning that the each node's(in batch) neighbor item id list #tmp_history_r is similar with tmp_history_uv, but record the rating score instead of item id for node in nodes: tmp_history_uv.append(self.history_uv_lists[int(node)]) tmp_history_r.append(self.history_r_lists[int(node)])
defforward(self, nodes, history_uv, history_r): # create a container for result, shpe of embed_matrix is (batchsize,embed_dim) embed_matrix = torch.empty(len(history_uv), self.embed_dim, dtype=torch.float).to(self.device)
# deal with each single nodes' neighbors for i inrange(len(history_uv)): history = history_uv[i] num_histroy_item = len(history) tmp_label = history_r[i]
# e_uv : turn neighbors id to embedding # uv_rep : turn single node to embedding if self.uv == True: # user component e_uv = self.v2e.weight[history] uv_rep = self.u2e.weight[nodes[i]] else: # item component e_uv = self.u2e.weight[history] uv_rep = self.v2e.weight[nodes[i]]
# get rating score embedding e_r = self.r2e.weight[tmp_label] # concatenated rating and neighbor, and than through two layers mlp to get xia x = torch.cat((e_uv, e_r), 1) x = F.relu(self.w_r1(x))
defforward(self, node1, u_rep, num_neighs): # pi uv_reps = u_rep.repeat(num_neighs, 1) # concatenated neighbot and pi x = torch.cat((node1, uv_reps), 1) # through 3 layers MLP x = F.relu(self.att1(x)) x = F.dropout(x, training=self.training) x = F.relu(self.att2(x)) x = F.dropout(x, training=self.training) x = self.att3(x) # get weights att = F.softmax(x, dim=0) return att
Social Aggregation
use the result of Item Aggregation and pi as input
defforward(self, nodes, to_neighs): #return a uninitialize matrix as result container, which shape is (batchsize, embed_dim) embed_matrix = torch.empty(len(nodes), self.embed_dim, dtype=torch.float).to(self.device)
for i inrange(len(nodes)): # get social graph neighbor tmp_adj = to_neighs[i] num_neighs = len(tmp_adj) # fase : can use user embedding instead of result of item aggregation to improve speed # e_u = self.u2e.weight[list(tmp_adj)] # fast: user embedding # slow: item-space user latent factor (item aggregation) feature_neigbhors = self.features(torch.LongTensor(list(tmp_adj)).to(self.device)) e_u = torch.t(feature_neigbhors)
u_rep = self.u2e.weight[nodes[i]] # concatenated node embedding and neigbor vector (result of item aggregation) # and than through MLPs and Softmax to calculate weights att_w = self.att(e_u, u_rep, num_neighs) # weight*neighbor vector att_history = torch.mm(e_u.t(), att_w).t() embed_matrix[i] = att_history to_feats = embed_matrix
return to_feats
Item Modeling
Similar with the Item Aggregation of User Modeling
#get nodes(batch) neighbors of item for node in nodes: tmp_history_uv.append(self.history_uv_lists[int(node)]) tmp_history_r.append(self.history_r_lists[int(node)])
defforward(self, nodes, history_uv, history_r): # create a container for result, shpe of embed_matrix is (batchsize,embed_dim) embed_matrix = torch.empty(len(history_uv), self.embed_dim, dtype=torch.float).to(self.device)
# deal with each single item nodes' neighbors for i inrange(len(history_uv)): history = history_uv[i] num_histroy_item = len(history) tmp_label = history_r[i]
# e_uv : turn neighbors(user node) id to embedding # uv_rep : turn single node(item node) to embedding if self.uv == True: # user component e_uv = self.v2e.weight[history] uv_rep = self.u2e.weight[nodes[i]] else: # item component e_uv = self.u2e.weight[history] uv_rep = self.v2e.weight[nodes[i]]
# get rating score embedding e_r = self.r2e.weight[tmp_label] # concatenated rating and neighbor, and than through two layers mlp to get fjt x = torch.cat((e_uv, e_r), 1) x = F.relu(self.w_r1(x))